Change-point study¶
Change point
analysis or
change detection
deals with abrupt changes in statistical properties of time series.
bayesloop includes two types abrupt changes: an abrupt change in
parameter values is modeled by the transition model Changepoint. In
contrast to this change in value, the transition model itself may change
at specific points in time, which we will refer to as structural
breaks. These structural changes are implemented using the
SerialTransitionModel class. The following two sections introduce
the ChangepointStudy class and describe its usage to analyze both
change-points and structural breaks in time series data.
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt # plotting
import seaborn as sns # nicer plots
sns.set_style('whitegrid') # plot styling
import bayesloop as bl
import numpy as np
Analyzing abrupt changes of parameter values¶
The ChangepointStudy class represents an extention of the
HyperStudy introduced above and provides an easy-to-use interface to
conduct change-point studies. By calling the fit method, this type
of study first analyzes the defined transition model and detects all
instances of the Changepoint class. Instead of directly using all
combinations of predefined change-points provided by the user, it then
computes a list of all valid combinations of change-point times and fits
them (basically preventing the double-counting of change-point times due
to reversed order). With Bayesian evidence as an objective fitness
measure, this type of study can be used to answer the general question
of when changes have happened. Furthermore, we may compute a
distribution of change-point times to assess the (un-)certainty of these
points in time.
Note: For simple change-point analyses with only one
change-/break-point or multiple change-/break-points which do not
“overlap”, using the HyperStudy class is sufficient, too.
Analysis of a single change-point¶
In a first example, we assume a single change-point in our data set of
coal mining disasters. Using the ChangepointStudy, we iterate over
all possible time steps using the change-point model. After processing
all time steps, the probability distribution of the change-point as well
as an average model are computed. This study may also be carried out
using MCMC methods, see e.g. the PyMC
tutorial for
comparison.
The change-point study is set up as shown below. Note that we supply the
value 'all' to the change-point hyper-parameter 'tChange',
indicating that all possible time steps are considered as a
change-point. One could of course also provide a list of possible
candidate time steps.
In [2]:
S = bl.ChangepointStudy()
S.loadExampleData()
L = bl.om.Poisson('accident_rate', bl.oint(0, 6, 1000))
T = bl.tm.ChangePoint('change_point', 'all')
S.set(L, T)
S.fit()
+ Created new study.
--> Hyper-study
--> Change-point analysis
+ Successfully imported example data.
+ Observation model: Poisson. Parameter(s): ['accident_rate']
+ Transition model: Change-point. Hyper-Parameter(s): ['change_point']
+ Detected 1 change-point(s) in transition model: ['change_point']
+ Set hyper-prior(s): ['uniform']
+ Started new fit.
+ 109 analyses to run.
+ Computed average posterior sequence
+ Computed hyper-parameter distribution
+ Log10-evidence of average model: -75.71555
+ Computed local evidence of average model
+ Computed mean parameter values.
+ Finished fit.
After all fits are completed, we can plot the change-point distribution,
by using the usual plot method. We may further use the eval
method to draw quantitative conclusions from the change-point
distribution:
In [3]:
plt.figure(figsize=(8, 4))
S.plot('change_point', color='g', alpha=.8)
plt.xlim([1875, 1905])
plt.xlabel('year')
p1 = S.eval('change_point < 1887')
p2 = S.eval('change_point > 1893')
# compute probability of change-point between 1887 and 1893
print('Probability of change-point between 1887 and 1893: {}'.format(1.-p1-p2))
P(change_point < 1887) = 0.099250764569
P(change_point > 1893) = 0.0616571951525
Probability of change-point between 1887 and 1893: 0.839092040278
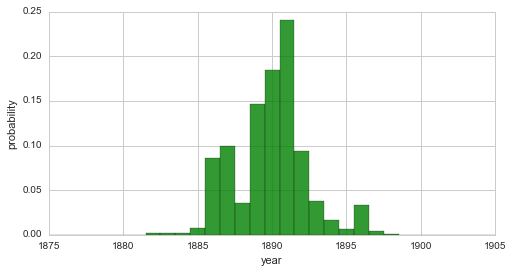
From this distribution, we may conclude that a change in safety conditions of coal mines in the UK happened during the seven-year interval from 1887 to 1893 with a probability of \(\approx 84\%\).
bayesloop further weighs all fitted models by their probability from
the change-point distribution and subsequently adds them up, resulting
in an average model, which is stored in S.posteriorSequence and
S.posteriorMeanValues. Additionally, the log-evidence of the average
model is set by the weighted sum of all log-evidence values. These
results can be plotted as before, using plot:
In [4]:
plt.figure(figsize=(8, 4))
plt.bar(S.rawTimestamps, S.rawData, align='center', facecolor='r', alpha=.5)
S.plot('accident_rate')
plt.xlim([1851, 1962])
plt.xlabel('year');
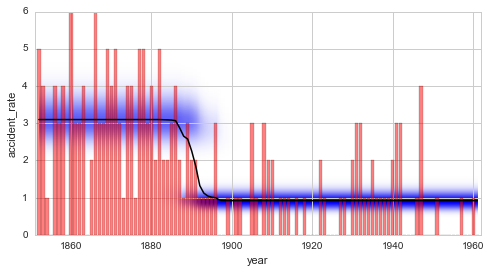
Exploring possible change-points¶
The change-point study described above explicitly assumes the existence of a single change-point in the data set. Without any prior knowledge about the data, however, this assumption can rarely be made with certainty as the number of potential change-points is often unknown.
In order to explore possible change-points without prior knowledge,
bayesloop includes the transition model RegimeSwitch, which
assigns a minimal probability (specified on a log10-scale by
log10pMin, relative to the probability value of a flat distribution)
to all parameter values on the parameter grid at every time step. This
model allows for abrupt parameter changes only, and neglects gradually
varying parameter dynamics. Note that no ChangepointStudy is needed
for this kind of analysis, the “standard” Study class is
sufficient.
For the coal mining example, the results from the regime-switching model with a minimal probability of \(10^{-7}\) resemble the average model of the change-point study:
In [5]:
S = bl.Study()
S.loadExampleData()
L = bl.om.Poisson('accident_rate', bl.oint(0, 6, 1000))
T = bl.tm.RegimeSwitch('log10pMin', -7)
S.set(L, T)
S.fit()
plt.figure(figsize=(8, 4))
plt.bar(S.rawTimestamps, S.rawData, align='center', facecolor='r', alpha=.5)
S.plot('accident_rate')
plt.xlim([1851, 1962])
plt.xlabel('year');
+ Created new study.
+ Successfully imported example data.
+ Observation model: Poisson. Parameter(s): ['accident_rate']
+ Transition model: Regime-switching model. Hyper-Parameter(s): ['log10pMin']
+ Started new fit:
+ Formatted data.
+ Set prior (function): jeffreys. Values have been re-normalized.
+ Finished forward pass.
+ Log10-evidence: -80.63781
+ Finished backward pass.
+ Computed mean parameter values.
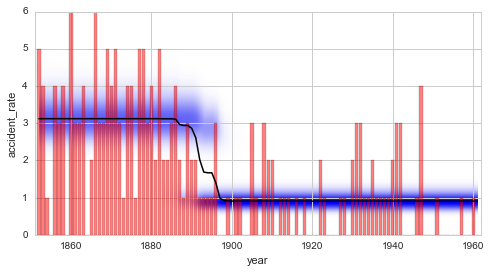
Analysis of multiple change-points¶
Suppose the regime-switching process introduced above indicates two
distinct change-points in a data set. In this case, the
ChangepointStudy class can be used together with a
CombinedTransitionModel to perform a comprehensive analysis assuming
two change-points. The combined transition model here simply consists of
two instances of the ChangePoint model. We use the example below to
investigate possible change-points in the disaster rate after the
significant decrease at the end of the 19th century, i.e. restricting
the data set to the time after 1900. Note that the ChangepointStudy
will only consider combinations of change-points that are in ascending
temporal order, i.e. the second change-point must occur after the first
one.
After all fits are done, the resulting joint change-point distribution
can be plotted using the getJointHyperParameterDistribution
(getJHPD) method (similar to plotting the joint distribution of a
hyper-study).
In [6]:
S = bl.ChangepointStudy()
S.loadExampleData()
mask = S.rawTimestamps > 1900 # select timestamps greater than the year 1900
S.rawTimestamps = S.rawTimestamps[mask]
S.rawData = S.rawData[mask]
L = bl.om.Poisson('accident_rate', bl.oint(0, 6, 1000))
T = bl.tm.CombinedTransitionModel(bl.tm.ChangePoint('t_1', 'all'),
bl.tm.ChangePoint('t_2', 'all'))
S.set(L, T)
S.fit()
S.getJHPD(['t_1', 't_2'], plot=True, color=[0.1, 0.8, 0.1])
plt.xlim([1899, 1962])
plt.ylim([1899, 1962])
# set proper view-point
ax = plt.gca()
ax.view_init(elev=35, azim=150)
+ Created new study.
--> Hyper-study
--> Change-point analysis
+ Successfully imported example data.
+ Observation model: Poisson. Parameter(s): ['accident_rate']
+ Transition model: Combined transition model. Hyper-Parameter(s): ['t_1', 't_2']
+ Detected 2 change-point(s) in transition model: ['t_1', 't_2']
+ Set hyper-prior(s): ['uniform', 'uniform']
+ Started new fit.
+ 1770 analyses to run.
+ Computed average posterior sequence
+ Computed hyper-parameter distribution
+ Log10-evidence of average model: -34.85781
+ Computed local evidence of average model
+ Computed mean parameter values.
+ Finished fit.
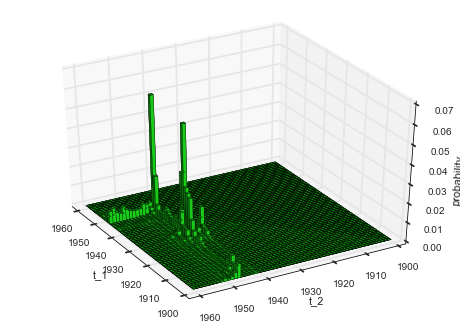
Instead of focusing on the exact time steps of the change-points, some
applications may call for the analysis of the time interval between two
change-points. The ChangepointStudy class provides a method called
getDurationDistribution which computes the probabilities of
different time intervals between two change-points and optionally plots
them in a bar graph. Based on the example above, the resulting
“duration distribution” is shown below:
In [7]:
plt.figure(figsize=(8, 4))
S.getDurationDistribution(['t_1', 't_2'], plot=True, color='g', alpha=.8)
plt.xlim([0, 62]);
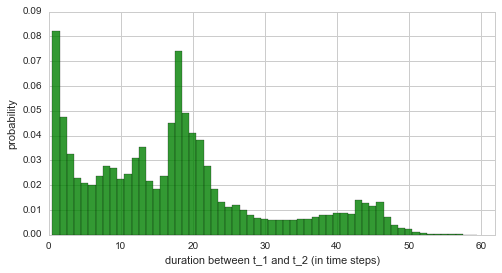
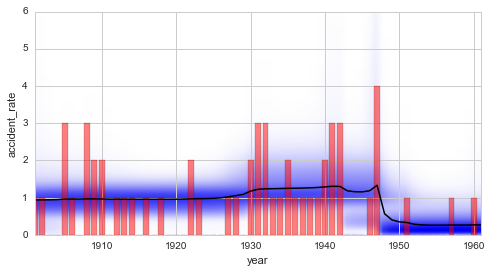
Finally, we plot the averaged parameter evolution of the two-change-point model. From the duration distribution as well as from the temporal evolution of the inferred disaster rate we may conclude that there is indeed a time period with a slightly increased disaster rate, which begins in \(\approx\) 1930 and ends in \(\approx\) 1945. The duration distribution underlines this finding with high probability values for durations up to 20 years.
In [8]:
plt.figure(figsize=(8, 4))
plt.bar(S.rawTimestamps, S.rawData, align='center', facecolor='r', alpha=.5)
S.plot('accident_rate')
plt.xlim([1901, 1961])
plt.xlabel('year');
Analyzing structural breaks in time series models¶
In contrast to a pure change in parameter value, the whole type of
parameter dynamics may change at a given point in time. We will use the
term structural break to describe such events. We have already
investigated so-called serial transition models that describe parameter
dynamics which change from time to time. While these serial transition
models are a re-occurring topic in this tutorial (see
here,
here and
here), the times at which the structural breaks
happen have - up to this point - always been user-defined and fixed.
This restriction can be lifted by the ChangepointStudy class. If a
SerialTransitionModel is defined within the change-point study, all
structural breaks will be treated as variables and the fit method
will iterate over all possible combinations, just as with “normal”
change-points.
In this section, our goal is to build a model to determine how long it took for the disaster rate to decrease from \(\approx\) 3 disasters per year to only \(\approx\) 1 per year. This kind of study may generally be applied to assess the effectivity of policies like safety regulations. Here, we devise a simple serial transition model that consists of three phases to describe the change in the annual number of coal mining disasters: in the first and the last phase, we assume a constant disaster rate, while the intermediate phase is modeled by a linear decrease of the disaster rate. By providing multiple values for the slope of the intermediate phase, we can combine the advantages of both hyper- and change-point study in order to consider the uncertainty of the change-points and the uncertainty of the slope of the intermediate phase. We restrict the data set to the years from 1870 to 1910, and assume an improvement of the disaster rate by 0 to 2.0 disasters per year.
*Note: The following analysis consists of ~25000 individual model fits. It may take several minutes to complete.*
In [9]:
S.loadExampleData()
mask = (S.rawTimestamps >= 1870)*(S.rawTimestamps <= 1910) # restrict analysis to 1870-1910
S.rawTimestamps = S.rawTimestamps[mask]
S.rawData = S.rawData[mask]
T = bl.tm.SerialTransitionModel(bl.tm.Static(),
bl.tm.BreakPoint('t_1', 'all'),
bl.tm.Deterministic(lambda t, slope=np.linspace(-2.0, 0.0, 30): t*slope,
target='accident_rate'),
bl.tm.BreakPoint('t_2', 'all'),
bl.tm.Static()
)
S.set(T)
S.fit()
S.getJHPD(['t_1', 't_2'], plot=True, color=[0.1, 0.8, 0.1])
plt.xlim([1869, 1911])
plt.ylim([1869, 1911])
# set proper view-point
ax = plt.gca()
ax.view_init(elev=35, azim=125)
+ Successfully imported example data.
+ Transition model: Serial transition model. Hyper-Parameter(s): ['slope', 't_1', 't_2']
+ Detected 2 break-point(s) in transition model: ['t_1', 't_2']
+ Set hyper-prior(s): ['uniform', 'uniform', 'uniform']
+ Started new fit.
+ 23400 analyses to run.
! WARNING: Posterior distribution contains only zeros, check parameter boundaries!
Stopping inference process. Setting model evidence to zero.
+ Computed average posterior sequence
+ Computed hyper-parameter distribution
+ Log10-evidence of average model: -30.63948
+ Computed local evidence of average model
+ Computed mean parameter values.
+ Finished fit.
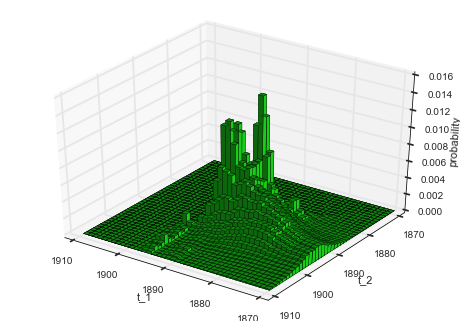
Apart from this rather non-intuitive joint distribution of the two structural break times, we can also plot the marginal distribution of the inferred slope of the intermediate phase:
In [10]:
plt.figure(figsize=(8,4))
S.plot('slope', color='g', alpha=.8)
plt.xlim([-2.1, 0.1]);
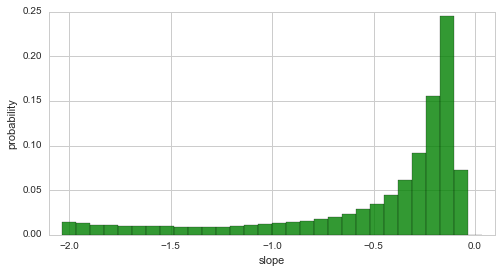
The plot above indicates that the decrease of the disaster rate is indeed a gradual process, as high probabilities are assigned to rather small slopes with an absolute value < 0.5. However, there is still a significant probability of slopes with an absolute value that is larger than 0.5:
In [11]:
S.eval('abs(slope) > 0.5');
P(abs(slope) > 0.5) = 0.29265010301
More intuitive than the slope is the duration between the two structural breaks. This period of time directly measures the time it takes for the disaster rate to decrease from three to one disaster per year. The plot below shows the distribution for this period of time:
In [12]:
plt.figure(figsize=(8,4))
d, p = S.getDurationDistribution(['t_1', 't_2'], plot=True, color='g', alpha=.8)
plt.xlim([-0.5, 40.5]);
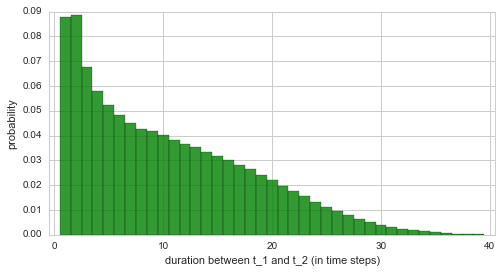
From this plot, we see that the period between the two structural breaks cannot be inferred with great accuracy. The accuracy may be improved by extending the simple serial model used in this example or by incorporating more data points (only 40 data points have been used here). We may still conclude that this analysis indicates an intermediate phase of improvement that is shorter than 15 years, with a probability of \(\approx 70\%\):
In [13]:
np.sum(p[np.abs(d) < 15])
Out[13]:
0.71545710930129347
The results from the break-point analysis are further illustrated by the temporal evolution of the inferred disaster rate. Below, the average model of the complete analysis is used to display the inferred changes in the disaster rate:
In [14]:
plt.figure(figsize=(8, 4))
plt.bar(S.rawTimestamps, S.rawData, align='center', facecolor='r', alpha=.5)
S.plot('accident_rate')
plt.xlim([1870, 1910])
plt.xlabel('year');
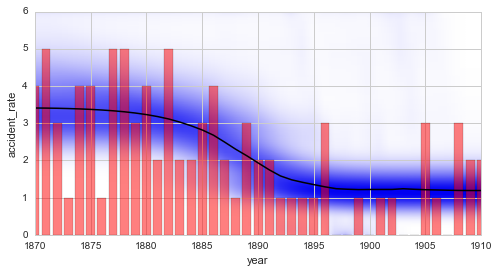
Finally, we want to stress the difference between change-points and
break-points again: If the BreakPoint transition model is used
within the SerialTransitionModel class, different transition models
will be specified before and after the break-point, but the parameter
values will not be reset at the break-point. In contrast, the
ChangePoint transition model can also be used in a
SerialTransitionModel (not shown in this tutorial). In addition to
the different parameter dynamics before and after the change-point, this
case allows for an abrupt change of the parameter values. Finally, if
the ChangePoint model is used without a SerialTransitionModel,
the parameter dynamics will stay the same before and after the
change-point, but an abrupt change of the parameter values is expected.